
The cocktail party phenomenon has long puzzled scientists
Imagine: you’re standing in a noisy hall, dozens of people are talking simultaneously, music is playing, glasses are clinking. And yet you calmly carry on a conversation with a friend, clearly distinguishing their voice amid the chaos of sounds. How does the brain handle this task, which no computer can replicate to this day? The answer lies in an amazing psychological phenomenon — the cocktail party effect.
What Is the Cocktail Party Effect
The cocktail party effect is our ability to focus on a single conversation even when numerous other voices and sounds are heard around us. In psychology, this phenomenon is also called selective auditory attention. Essentially, the brain works like an invisible sound engineer: it “turns up the volume” on the voice you need and “mutes” everything else.
In everyday life, we encounter this constantly. A conversation in a café, chatting at a birthday party, a discussion at a work meeting where everyone talks at once — each time the brain imperceptibly filters out the excess and lets you follow a single thread of conversation. This is such a natural process that we don’t even notice how complex the work it performs really is.
And here’s what’s curious: this task, which a healthy person solves with no apparent effort, still remains a serious challenge for engineers and programmers. Voice assistants, speech recognition systems, and hearing aids still fall short of the living brain when it comes to separating voices in a crowd.
How Scientists Discovered the Cocktail Party Phenomenon
The history of research into this effect began not at a party, but in an airport control tower. In the early 1950s, air traffic controllers received messages from pilots through a single shared loudspeaker. The voices of several pilots blended together, and figuring out who was saying what was extremely difficult — and a mistake could cost lives.
This practical problem caught the interest of British psychologist Colin Cherry. In 1953, he published a paper in which he first described and named the phenomenon — the cocktail party problem.
Cherry proposed that humans separate voices by relying on several cues:
- the direction from which the sound comes;
- body language — gestures, lip movements;
- differences in voices — pitch, speech rate, male or female voice;
- differences in accent;
- context and language knowledge — the ability to “guess” missed words based on the meaning of the phrase.
To test the last factor, researchers recorded two different messages in the same voice and played them through headphones simultaneously. The resulting “jumble” of words sounded almost unintelligible. But subjects could still isolate one of the messages if they concentrated on it. This indicated that our brain is excellent at predicting words from context, filling in the gaps in what is heard.
How the Brain Filters Voices in Noise
After Cherry’s initial experiments, he and his followers began testing the remaining factors one by one. The results turned out to be unexpected.
Sound direction in laboratory conditions didn’t help as much as one might expect. When subjects received different messages in the right and left ears, many struggled to ignore the “unnecessary” channel. However, in real life, where there are far more than two sound sources, the spatial location of the speaker does play a role: it’s easier for us to follow a voice if the person stays in one place.
Differences in voices — timbre, pitch, speed — turned out to be much more significant. Subjects reliably noticed when the voice in the “ignored” channel changed from male to female or vice versa. However, changes in accent or even language went almost unnoticed by participants. In one experiment with bilingual volunteers, they didn’t even notice when the speech in the second channel suddenly switched from English to German. Even more surprisingly, when the “background” message was played backwards, most subjects didn’t notice — though some said it sounded “a bit strange.”
Thus, the brain’s main tools for filtering are: knowledge of language, which allows predicting words from context, and the physical characteristics of the speaker’s voice. Visual cues like facial expressions, gestures, and lip movements also help, because they give the brain additional context for “guessing” missed words.
Why We Hear Our Own Name Even in Someone Else’s Conversation
One of the most vivid examples of the cocktail party effect is familiar to everyone: you’re engrossed in conversation in a noisy group, and suddenly somewhere behind you someone says your name. You react instantly — even though a second ago you weren’t listening to other people’s conversations at all.
This phenomenon became a serious challenge for one of the first models of attention. In 1958, psychologist Donald Broadbent proposed the filter model: in his view, the brain completely screens out unimportant information before it is processed at the level of meaning. The filter works on simple physical features — volume, tone, direction of sound. If a stimulus doesn’t pass the selection, it is discarded.
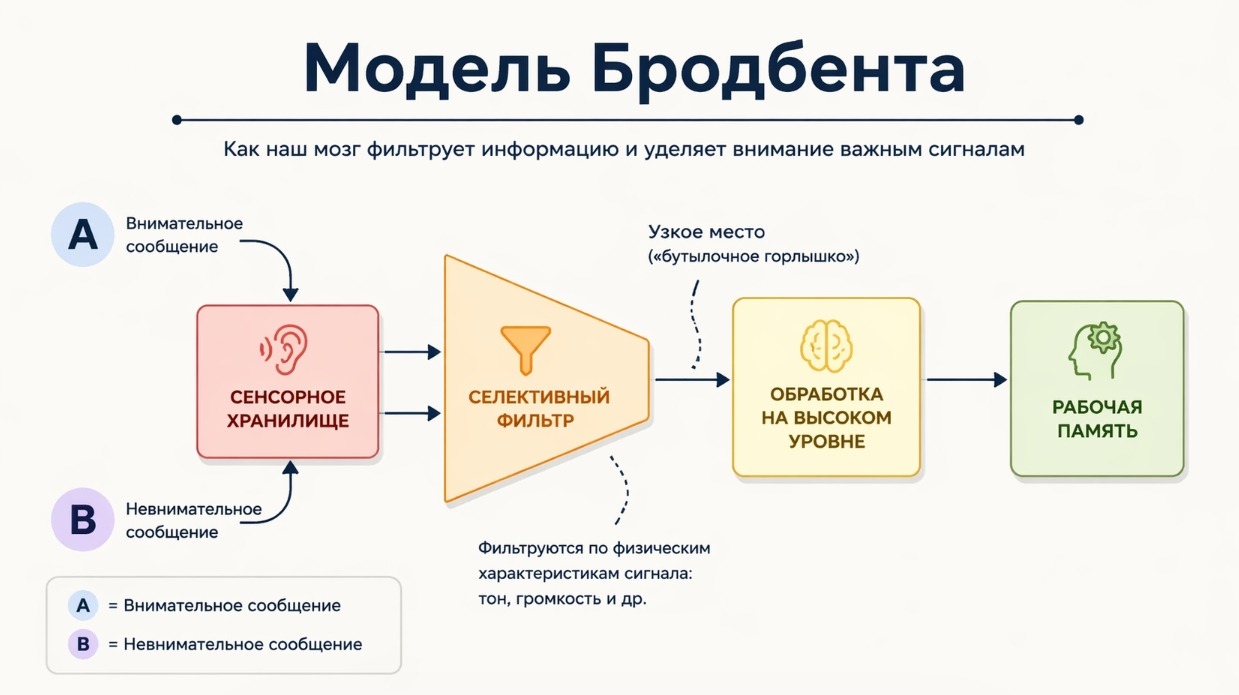
Broadbent’s model
But if Broadbent’s model were entirely correct, hearing your own name in someone else’s conversation would be impossible — after all, you didn’t select it for processing. Yet people regularly do this. This means the brain does analyze background sounds more deeply than Broadbent assumed — at least checking them for personal significance.
However, research has shown that this ability is not absolute. According to one experiment, approximately two-thirds of subjects did not notice their own name spoken in the “ignored” channel. Those who did notice tended to be people with more scattered attention — their brains simply did a worse job of blocking background signals.
Today it is believed that the brain doesn’t discard background sounds entirely but rather “mutes” them. If something personally significant appears in the muted stream — a name, a familiar voice, the word “fire” — the attention system switches instantly. It’s a kind of alarm system running in the background.
How Age and Hearing Loss Affect Voice Filtering
For most people with normal hearing, voice filtering is such an automatic process that you don’t think about it. But there are situations when it stops working.
With age, the ability for selective hearing declines. Elderly people find it harder to pick out speech from background noise, even if formally their hearing is within normal range. The brain processes competing sound streams more slowly and copes less well with suppressing unnecessary voices.

The cocktail party effect works better in younger people
People with hearing impairments face an even more serious problem. For them, a multi-voice environment is not just background noise but a practically insurmountable obstacle. Research has shown that with hearing loss, the ears can merge different sounds into a single unintelligible signal — a phenomenon called binaural pitch fusion. Instead of separating voices, the brain blends them, and conversation in a crowd becomes agonizing.
Furthermore, for the cocktail party effect to work, it’s important to hear with both ears. The brain compares signals from the right and left ears — the difference in arrival time, in volume — and uses this to determine where the sound is coming from. People with unilateral hearing loss are noticeably worse at separating voices.
How to Use the Cocktail Party Effect in Life
Behind the cocktail party effect lies one of the most complex and not yet fully solved problems in brain science: how exactly neurons separate, group, and select sound streams in real time.
Understanding this mechanism has quite practical implications. Engineers use research on this effect to create better hearing aids with artificial intelligence features that learn to suppress background noise and amplify the speaker’s voice. Voice assistant developers are improving voice separation algorithms so that devices can better “hear” you in noisy surroundings.
And for the average person, it’s useful to know a simple thing: if you want to be better understood in a noisy place, face your listener, speak a little slower, and don’t change your position in space. Your listener’s brain latches onto visual cues, familiar timbre, and consistent spatial location of the sound source.


